Question 1
(a) Define data structure. List the various linear and non-linear data structures and explain them in brief. The possible ways in which the data items or atoms are logically related define data
structures.
Linear Data Structures: Array, Stack, Queue, Linked List.
Non-Linear Data Structures: Tree, Graph.
Following are the Linear Data Structures:
Array: An array is an ordered set which consists of a fixed number of objects. No
deletion or insertion operations are performed on arrays.
Stack: A collection of items in which only the most recently added item may be
removed. The latest added item is at the top. Basic operations are push and pop. Also
known as "last-in, first-out" or LIFO.
Queue: A collection of items in which only the earliest added item may be accessed.
Basic operations are add (to the tail) or enqueue and delete (from the head) or dequeue.
Delete returns the item removed. Also known as "first-in, first-out" or FIFO.
Linked List: A list implemented by each item having a link to the next item.
Following are the Non-Linear Data Structures:
Tree: A data structure accessed beginning at the root node. Each node is either a leaf or
an internal node. An internal node has one or more child nodes and is called the parent
of its child nodes. All children of the same node are siblings. Contrary to a physical tree,
the root is usually depicted at the top of the structure, and the leaves are depicted at the
bottom.
Graph: A
 Graph: A set of items connected by edges. Each item is called a vertex or node.
Formally, a graph is a set of vertices and a binary relation between vertices, adjacency.
Graph: A set of items connected by edges. Each item is called a vertex or node.
Formally, a graph is a set of vertices and a binary relation between vertices, adjacency.
(b) Discuss the basic operations performed with linear structure.
Following are the basic operations with linear structure:
1.) Traversing: It means passing through the every element one by one which stored in
the particular structure.
2.) Insertion: It means to insert an element in the particular structure.
3.) Deletion: It means to delete an element in the particular structure.
4.) Searching: It means to find desired element which is stored in the particular
structure.
5.) Sorting: It means to arrange the elements of the particular structure in
ascending/descending order.
Question 2
(a) Write an algorithm to convert infix expression to postfix expression.Given an input string INFIX representing an infix expression whose single character symbols have precedence values and ranks as given in table. A vector S representing a Stack. A string function NEXTCHAR which, when invoked, returns the next character of the input string. This algorithm converts the string INFIX to its reverse Polish string equivalent, POLISH. RANK contains the value of rank of the reverse Polish string. NEXT contains the symbol being examined. TEMP is a temporary variable which contains the unstacked element. We assume that the given input string is padded on the right with the special symbol ‘)’. Algorithms PUSH and POP are used for stack manipulations.
Step-1: [Initialize the stack] TOP 1 S[TOP] ‘(’
Step-2: [Initialize output string and rank count] POLISH ‘’ RANK 0
Step-3: [Get first input symbol] NEXT NEXTCHAR(INFIX)
Step-4: [Translate the infix expression] Repeat thru Step-7 while NEXT ‘’
Step-5: [Remove symbols with greater precedence from stack]
If TOP < 1 then Write(‘INVALID’)
Exit
Repeat while f(NEXT) < g(S[TOP])
TEMP POP(S, TOP) POLISH POLISH O TEMP RANK RANK + r(TEMP)
If RANK < 1 then
Write(‘INVALID’)
Exit
Step-6: [Are there matching parenthesis?] If f(NEXT) g(S[TOP]) then Call PUSH(S, TOP, NEXT) else POP(S,TOP)
Step-7: [Get next input symbol] NEXT NEXTCHAR(INFIX)
Step-8: [Is the expression valid?] If TOP 0 or RANK 1 then Write(‘INVALID’) else Write(‘VALID’) Exit
(b)Write an algorithm for evaluation of postfix expression and evaluation the following
expression showing every status of stack in tabular form.
(i) 5 4 6 + * 4 9 3 / + *
(ii) 7 5 2 + * 4 1 1 + / -
(i) 5 4 6 + * 4 9 3 / + *
| Character Scanned | Contents of Stack | Intermediate Result |
|---|---|---|
| 5 | 5 | |
| 5 | 5 4 | |
| 6 | 5 4 6 | 4 + 6 = 10 |
| + | 5 10 | 5 * 10 = 50 |
| * | 50 | |
| 4 | 50 4 | |
| 9 | 50 4 9 | |
| 3 | 50 4 9 3 | 9 / 3 = 3 |
| / | 50 4 3 | 4 + 3 = 7 |
| + | 50 7 | 50 * 7 = 350 |
| * | 350 |
(ii) 7 5 2 + * 4 1 1 + / -
| Character Scanned | Contents of Stack | Intermediate Result |
|---|---|---|
| 7 | 7 | |
| 5 | 7 5 | |
| 2 | 7 5 2 | 5 + 2 = 7 |
| + | 7 7 | 7 * 7 = 49 |
| * | 49 | |
| 4 | 49 4 | |
| 1 | 49 4 1 | |
| 1 | 49 4 1 1 | 1 + 1 = 2 |
| + | 49 4 2 | 4 / 2 =2 |
| / | 49 2 | 49 – 2 = 47 |
| - | 47 |
b) Trace the conversion of infix to postfix form in tabular form.
(i) ( A + B * C / D - E + F / G / ( H + I ) )
(ii) ( A + B ) * C + D / ( B + A * C ) + D
(i) ( A + B * C / D - E + F / G / ( H + I ) ) )
| Character Scanned | Contents of Stack | Reverse Polish Expression | Rank |
|---|---|---|---|
| ( | |||
| ( | ( ( | ||
| A | ( ( A | ||
| + | ( ( + | A | 1 |
| B | ( ( + B | A | 1 |
| * | ( ( + * | AB | 2 |
| C | ( ( + * C | AB | 2 |
| / | ( ( + / | ABC* | 2 |
| D | ( ( + / D | ABC* | 2 |
| - | ( ( - | ABC*D/+ | 1 |
| E | ( ( - E | ABC*D/+ | 1 |
| + | ( ( + | ABC*D/+E- | 1 |
| F | ( ( + F | ABC*D/+E- | 1 |
| / | ( ( + / | ABC*D/+E-F | 2 |
| G | ( ( + / G | ABC*D/+E-F | 2 |
| / | ( ( + / | ABC*D/+E-FG/ | 2 |
| ( | ( ( + / ( | ABC*D/+E-FG/ | 2 |
| H | ( ( + / ( H | ABC*D/+E-FG/ | 2 |
| + | ( ( + / ( + | ABC*D/+E-FG/H | 3 |
| I | ( ( + / ( + I | ABC*D/+E-FG/H | 3 |
| ) | ( ( + / | ABC*D/+E-FG/HI+ | 3 |
| ) | ( | ABC*D/+E-FG/HI+/+ | 1 |
| ) | ABC*D/+E-FG/HI+/+ | 1 |
ANSWER : ABC*D/+E-FG/HI+/+ (ii) ( A + B ) * C + D / ( B + A * C ) + D
| Character Scanned | Contents of Stack | Reverse Polish Expression | Rank |
|---|---|---|---|
| ( | |||
| ( | ( ( | ||
| A | ( ( A | ||
| + | ( ( + | A | 1 |
| B | ( ( + B | A | 1 |
| ) | ( | AB+ | 1 |
| * | ( * | AB+ | 1 |
| C | ( * C | AB+ | 1 |
| + | ( + | AB+C* | 1 |
| D | ( + D | AB+C* | 1 |
| / | ( + / | AB+C*D | 2 |
| ( | ( + / ( | AB+C*D | 2 |
| B | ( + / ( B | AB+C*D | 2 |
| + | ( + / ( + | AB+C*DB | 3 |
| A | ( + / ( + A | AB+C*DB | 3 |
| * | ( + / ( + * | AB+C*DBA | 4 |
| C | ( + / ( + * C | AB+C*DBA | 4 |
| ) | ( + / | AB+C*DBAC*+ | 3 |
| + | ( + | AB+C*DBAC*+/+ | 1 |
| D | ( + D | AB+C*DBAC*+/+ | 1 |
| ) | AB+C*DBAC*+/+D+ | 1 |
Question 3
(a)Explain following:(i) DQUEUE, (ii) Priority Queue, (iii) Circular Queue.
(i) DQUEUE: It is a double-ended queue. Items can be inserted and deleted from either
ends. More versatile data structure than stack or queue. E.g. policy-based application
(e.g. low priority go to the end, high go to the front)
(ii) Priority Queue: More specialized data structure. Similar to Queue, having front and
rear. Items are removed from the front. Items are ordered by key value so that the item
with the lowest key (or highest) is always at the front. Items are inserted in proper
position to maintain the order.
(iii) Circular Queue: When a new item is inserted at the rear, the pointer to rear moves
upwards. Similarly, when an item is deleted from the queue the front arrow moves
downwards. After a few insert and delete operations the rear might reach the end of the
queue and no more items can be inserted although the items from the front of the queue
have been deleted and there is space in the queue. To solve this problem, queues
implement wrapping around. Such queues are called Circular Queues. Both the front
and the rear pointers wrap around to the beginning of the array.
(b) Write the implementation procedure of basic primitive operations of the stack using:
(i) Linear array, (ii) Linked List.
• Implementation Procedure of the Stack Using Linear Array:
Procedure PUSH(S, TOP, X) :- This procedure inserts an element X to the top of a
stack. Stack is represented by a vector S containing N elements. TOP is a pointer to the
top element in the stack.
Step-1: [Check for Stack Overflow]
If TOP N
then Write(‘STACK OVERFLOW’)
Return
Step-2: [Increment TOP]
TOP TOP + 1
Step-3: [Insert an element]
S[TOP] X
Step-4: [Finished]
Return
Function POP(S, TOP) :- This function deletes and returns the top element of a stack.
Stack is represented by a vector S. TOP is a pointer to the top element in the stack. X is
a temporary variable.
Step-1: [Check for Stack Underflow]
If TOP = 0 then
Write(‘STACK UNDERFLOW’)
Return(0) (0 denotes empty stack)
Step-2: [Delete top element of stack]
X S[TOP]
Step-3: [Decrement TOP]
TOP TOP – 1
Step-4: [Return top element of stack]
Return(X)
(C) Consider the following arithmetic expression P, written in postfix notation. Translate it in infix notation and evaluate. P: 12, 7, 3, -, /, 2, 1, 5, +, *, +
P: 12, 7, 3, -, /, 2, 1, 5, +, *, +
12, (7 – 3), /, 2, 1, 5, +, *, +
(12 / (7 – 3)), 2, 1, 5, +, *, +
(12 / (7 – 3)), 2, (1 + 5), *, +
(12 / (7 – 3)), (2 * (1 + 5)), +
(12 / (7 – 3)) + (2 * (1 + 5))
= (12 / 4) + (2 * (1 + 5))
= 3 + (2 * (1 + 5))
= 3 + (2 * 6)
= 3 + 12
= 15
OR
Question 3
(b) Write the implementation procedure of basic primitive operations of the queue using: (i) Linear array, (ii) Linked List.Implementation Procedure of the Queue Using Linear Array:
Procedure QINSERT(Q, F, R, N, Y) :- Given F and R, pointers to the front and rear
elements of a queue, respectively. Queue is represented by a vector Q consisting of N
elements, and an element Y. This procedure inserts Y at the rear of the queue. Initially,
F and R set to zero.
Step-1: [Check for Queue Overflow]
If R≥ N
then Write(‘OVERFLOW’)
Return
Step-2: [Increment rear pointer]
R← R + 1
Step-3: [Insert an element]
Q(R)← Y
Step-4: [Is front pointer properly set?]
If F = 0
then F← 1
Return
Function QDELETE(Q, F, R) :- Given F and R, pointers to the front and rear elements
of a queue, respectively. Queue is represented by a vector Q. This function deletes and
returns the last element of the queue. Y is a temporary variable.
Step-1: [Check for Queue Underflow]
If F = 0
then Write(‘UNDERFLOW’)
Return(0) (0 denotes an empty queue)
Step-2: [Delete an element]
Y←Q[F]
Step-3: [Is queue empty?]
If F = R
then F←R←0
else F←F + 1
Step-4: [Return an element]
Return(Y)
(C) Discuss advantages and disadvantages of linked list over array.
Advantages of Linked List over Array:::
1 . Access :Random / Sequential
Stack elements can be randomly Accessed using Subscript Variable
e.g a[0],a[1],a[3] can be randomly accessed
While In Linked List We have to Traverse Through the Linked List for Accessing
Element. So O(n) Time required for Accessing Element .
Generally In linked List Elements are accessed Sequentially.
2 . Memory Structure :
Stack is stored in contiguous Memory Locations , i.e Suppose first element is
Stored at 2000 then Second Integer element will be stored at 2002 .
But It is not necessary to store next element at the Consecutive memory
Location .
Element is stored at any available Location , but the Pointer to that memory
location is stored in Previous Node.
3 . Insertion / Deletion
As the Array elements are stored in Consecutive memory Locations , so While
Inserting elements ,we have to create space for Insertion.
So More time required for Creating space and Inserting Element
Similarly We have to Delete the Element from given Location and then Shift All
successive elements up by 1 position.
In Linked List we have to Just Change the Pointer address field (Pointer),So
Insertion and Deletion Operations are quite easy to implement.
4 . Memory Allocation :
Memory Should be allocated at Compile-Time in Stack . i.e at the time when
Programmer is Writing Program.
In Linked list memory can be allocated at Run-Time , i.e After executing
Program.
Stack uses Static Memory Allocation and Linked List Uses Dynamic Memory
Allocation.
Dynamic Memory allocation functions - malloc,calloc,delete etc...
Question 4
(a)Explain Sequential Files and Indexed Sequential Files Structures. • Sequential Files:-
1. A sequential file is designed for efficient processing of records in sorted order on
some search key. Records are chained together by pointers to permit fast retrieval
in search key order. Pointer points to next record in order. Records are stored
physically in search key order (or as close to this as possible). This minimizes
number of block accesses.
2. It is difficult to maintain physical sequential order as records are inserted and
deleted. Deletion can be managed with the pointer chains. Insertion poses problems
if no space where new record should go. If space, use it, else put new record in an
overflow block. Adjust pointers accordingly. Problem: we now have some records
out of physical sequential order. If very few records in overflow blocks, this will
work well. If order is lost, reorganize the file. Reorganizations are expensive and
done when system load is low.
3. If insertions rarely occur, we could keep the file in physically sorted order and
reorganize when insertion occurs. In this case, the pointer fields are no longer
required.
• Indexed Sequential Files:
Each record of a file has a key field which uniquely identifies that record.
An index consists of keys and addresses (physical disc locations).
An indexed sequential file is a sequential file (i.e. sorted into order of a key field) which
has an index.
A full index to a file is one in which there is an entry for every record.
Indexed sequential files are important for applications where data needs to be
accessed.....
• sequentially
• randomly using the index.
An indexed sequential file allows fast access to a specific record.
Example: A company may store details about its employees as an indexed sequential
file. Sometimes the file is accessed....
• sequentially. For example when the whole of the file is processed to produce
payslips at the end of the month.
• randomly. Maybe an employee changes address, or a female employee gets
married and changes her surname.
An indexed sequential file can only be stored on a random access device
eg magnetic disc, CD.
(b) Explain the Preorder, Inorder and Postorder traversal techniques of the binary tree with suitable example.
A tree is a non-empty set, one element of which is designated the root of the tree while
the remaining elements are partitioned into non-empty sets each of which is a subtree of
the root.
Binary Tree: Each node has zero, one, or two children. This assertion makes many tree
operations simple and efficient.
Traversal techniques of the binary tree
Many problems require we visit* the nodes of a tree in a systematic way: tasks such as
counting how many nodes exist or finding the maximum element. Three different
methods are possible for binary trees: preorder, postorder, and in-order, which all do
the same three things: recursively traverse both the left and rights subtrees and visit the
current node.
The difference is when the algorithm visits the current node:
preorder: Current node, left subtree, right subtree(DLR)
postorder: Left subtree, right subtree, current node(LRD)
in-order: Left subtree, current node, right subtree.(LDR)
• Visit means performing some operation involving the current node of a tree, like
incrementing a counter or checking if the value of the current node is greater than
any other recorded.
Sample implementations for Tree Traversal
preorder(node)
visit(node)
if node.left ≠ null then preorder(node.left)
if node.right ≠ null then preorder(node.right)
inorder(node)
if node.left ≠ null then inorder(node.left)
visit(node)
if node.right ≠ null then inorder(node.right)
postorder(node)
if node.left ≠ null then postorder(node.left)
if node.right ≠ null then postorder(node.right)
visit(node)
levelorder(root)
queue<node> q
q.push(root)
while not q.empty do
node = q.pop
visit(node)
if node.left ≠ null then q.push(node.left)
if node.right ≠ null then q.push(node.right)
Examples of Tree Traversals
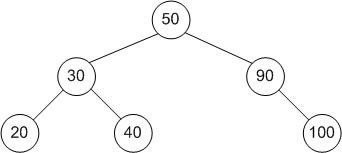 preorder: 50, 30, 20, 40, 90, 100
inorder: 20, 30, 40, 50, 90, 100
postorder: 20, 40, 30, 100, 90, 50
preorder: 50, 30, 20, 40, 90, 100
inorder: 20, 30, 40, 50, 90, 100
postorder: 20, 40, 30, 100, 90, 50
OR
(a) Explain the terms: File, Field, Record, Database, Key.File: A collection of data or information that has a name, called the filename. Almost all
information stored in a computer must be in a file. There are many different types of
files: data files, text files , program files, directory files, and so on. Different types of
files store different types of information. For example, program files store programs,
whereas text files store text.
Field: A space allocated for a particular item of information. A tax form, for example,
contains a number of fields: one for your name, one for your Social Security number,
one for your income, and so on. In database systems, fields are the smallest units of
information you can access. In spreadsheets, fields are called cells.
Most fields have certain attributes associated with them. For example, some fields are
numeric whereas others are textual, some are long, while others are short. In addition,
every field has a name, called the field name.
Record: In database management systems, a field can be required, optional, or
calculated. A required field is one in which you must enter data, while an optional field
is one you may leave blank. A calculated field is one whose value is derived from some
formula involving other fields. You do not enter data into a calculated field; the system
automatically determines the correct value.
A collection of fields is called a record.
Database: The definition of a database is a structured collection of records or data that is
stored in a computer system. In order for a database to be truly functional, it must not
only store large amounts of records well, but be accessed easily. In addition, new
information and changes should also be fairly easy to input. In order to have a highly
efficient database system, you need to incorporate a program that manages the queries
and information stored on the system. This is usually referred to as DBMS or a
Database Management System. Besides these features, all databases that are created
should be built with high data integrity and the ability to recover data if hardware fails.
(b)Which are the basic traversing techniques of the Graph? Write the algorithm of any one
of them?
Traversal is the facility to move through a structure visiting each of the vertices once.
We looked previously at the ways in which a binary tree can be traversed. Two possible
traversal methods for a graph are breadth-first and depth-first.
• Depth-First Traversal:
A depth-first traversal works in a similar way, except that the neighbors of each visited
vertex are added to a stack data structure. Vertices are visited in the order in which they
are popped from the stack, i.e. last-in, first-out.
• Algorithm of Depth-First Traversal:
1. Create an empty stack
2. Unmark all nodes
3. Mark the start node and place it on the stack
3. Loop while the stack is not empty
3.1 Remove a node, n, from the stack
3.2 Process node n
3.2 Loop for each of the nodes adjacent to n
3.2.1 If the node is unmarked then
3.2.1.1 Mark it and place it on the stack
4. Finish
• Breadth-First Traversal:
This method visits all the vertices, beginning with a specified start vertex. It can be
described roughly as “neighbors-first”. No vertex is visited more than once, and vertices
are only visited if they can be reached – that is, if there is a path from the start vertex.
Breadth-first traversal makes use of a queue data structure. The queue holds a list of
vertices which have not been visited yet but which should be visited soon. Since a
queue is a first-in first-out structure, vertices are visited in the order in which they are
added to the queue.
Visiting a vertex involves, for example, outputting the data stored in that vertex, and
also adding its neighbors to the queue. Neighbors are not added to the queue if they are
already in the queue, or have already been visited.
• Algorithm of Breadth-First Traversal:
1. Create an empty queue
2. Unmark all nodes
3. Mark the start node and place it on the queue
3. Loop while the queue is not empty
3.1 Remove a node, n, from the queue
3.2 Process node n
3.2 Loop for each of the nodes adjacent to n
3.2.1 If the node is unmarked then
3.2.1.1 Mark it and place it on the queue
4. Finish
Question 5
(a) Discuss following with reference to graphs. (i) Directed graph (ii) Undirected graph (iii) Degree of vertex (iv) Null graph(i) Directed Graph: In a directed graph, each edge has a sense of direction from u to v and is written as an ordered pair <u,v> or u→v. (ii) Undirected Graph: In an undirected graph, an edge has no sense of direction and is written as an unordered pair {u,v} or u<->v. (iii) Degree of Vertex: The number of edges with one endpoint on a given vertex is called that vertex's degree. In a directed graph, the number of edges that point to a given vertex is called its in-degree, and the number that point from it is called its out-degree. (iv) Null Graph: A graph which containing only isolated nodes is called null graph. In a graph, a node which is not adjacent to any other node is called an isolated node.
OR
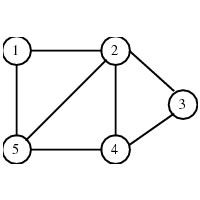
(a) Explain matrix and linked list representation of a graph.Graphs by Adjacency Matrices.
A graph G= can be represented by a |V|*|V| adjacency matrix A. If G is directed,
Aij=true if and only if <vi,vj> is in E. There are at most |V|2 edges in E.
1 2 3 4 5 6
1 T
2 T
3 T
4 T T T
5 T T T
6 T
Adjacency Matrix of Directed Graph.
If G is undirected, Aij=Aji=true if {vi,vj} is in E and Aij=Aji=false otherwise. In this case
there are at most |V|*(|V|+1)/2 edges in E, A is symmetric and space can be saved by
storing only the upper triangular part Aij for i>=j.
1 2 3 4 5 6
1 T T T
2 T T T T
3 T T
4 T T T T
5 T T T
6 T T
Adjacency Matrix of Undirected Graph.
1 2 3 4 5 6
1 T T T
2 T T T
3 T
4 T
5 T
6
Upper Triangular Adjacency Matrix of Undirected Graph.
An adjacency matrix is easily implemented as an array.
Both directed and undirected graphs may be weighted. A weight is attached to each
edge. This may be used to represent the distance between two cities, the flight time, the
cost of the fare, the electrical capacity of a cable or some other quantity associated with
the edge. The weight is sometimes called the length of the edge, particularly when the
graph represents a map of some kind. The weight or length of a path or a cycle is the
sum of the weights or lengths of its component edges. Algorithms to find shortest paths
in a graph are given later.
The adjacency matrix of a weighted graph can be used to store the weights of the edges.
If an edge is missing a special value, perhaps a negative value, zero or a large value to
represent "infinity", indicates this fact.
1 2 3 4 5 6
1 4
2 4
3 3
4 3 2 3
5 4 5 1
6 5
Adjacency Matrix of Weighted Directed Graph.
1 2 3 4 5 6
1 4 3 5
2 4 3 4 4
3 3 2
4 3 4 2 3
5 4 3 1
6 5 1
Adjacency Matrix of Weighted Undirected Graph.
1 2 3 4 5 6
1 4 3 5
2 3 4 4
3 2
4 3
5 1
6
Upper Triangular Adjacency Matrix of Weighted Undirected Graph.
It is often the case that if the weights represent distances then the natural distance from
vi to itself is zero and the diagonal elements of the matrix are given this value.
A weighted adjacency matrix is easily defined in any imperative programming
language.
A graph is complete if all possible edges are present. It is dense if most of the possible
edges are present. It is sparse if most of them are absent, |E|<<|V|2. Adjacency matrices
are space efficient for dense graphs but inefficient for sparse graphs when most of the
entries represent missing edges. Adjacency lists use less space for sparse graphs.
Graphs by Adjacency Lists.
In a sparse directed graph, |E|<<|V|2. In a sparse undirected graph |E|<<|V|*(|V|-1)/2.
Most of the possible edges are missing and space can be saved by storing only those
edges that are present, using linked lists.
Consider the weighted directed case.
An edge <vi,vj> is placed in a list associated with vi. The edge is represented by the
destination vj and the weight.
1:--------->2,4:nil
2:--------->4,4:nil
3:--------->2,3:nil
4:--------->1,3:----->3,2:----->5,3:nil
5:--------->4,5:----->6,1:nil
6:--------->1,5:nil
Adjacency Lists for Weighted Directed Graph.
Consider now the undirected case:
1:--------->2,4:----->4,3:----->6,5:nil
2:--------->1,4:-----:3,3:----->4,4:----->5,4:nil
3:--------->2,3:----->4,2:nil
4:--------->1,3:----->2,4:----->3,2:----->5,3:nil
5:--------->2,4:----->4,3:----->6,1:nil
6:--------->1,5:----->5,1:nil
Adjacency Lists for Weighted Undirected Graph.
As before, half the space can be saved by only storing {vi,vj} for i>=j:
1:--------->2,4:----->4,3:----->6,5:nil
2:--------->3,3:----->4,4:----->5,4:nil
3:--------->4,2:nil
4:--------->5,3:nil
5:--------->6,1:nil
6:nil
Reduced Adjacency Lists for Weighted Undirected Graph.
Adjacency lists can be defined using records (structs) and pointers.
Note that some questions, such as "are vi and vj adjacent in G", take more time to
answer using adjacency lists than using an adjacency matrix as the latter gives random
access to all possible edges. (b) Discuss following with reference to trees. (i) Height of the tree (ii) Binary tree.
(i) Height of the Tree: The height of a node is the longest path from that node to its leaves. The height of a tree is the height of the root. (ii) Binary tree: In binary tree, each node has zero, one, or two children.
Once you realise this it's time to start shopping
ReplyDeleteonline. Once you find a couple of insurance policies that you think to buy, it is time to make your final
choice, I personally recommend you choosing this insurance policy that
have the highest deductibles. Consider increasing your deductible to
reduce your premiums.
Feel free to visit my web blog cheap liability car insurance alabama